Snowflake 很高兴地宣布发布 Arctic Embed L 2.0 和 Arctic Embed M 2.0 ,这是我们前沿嵌入模型的下一次迭代,现在可以支持多语言搜索。虽然我们之前的版本受到了客户、合作伙伴和开源社区的欢迎,并实现了数百万次的下载,但我们一直收到一个请求:你们能否使这个模型支持多语言?Arctic Embed 2.0 在我们之前版本强大的基础上构建,增加了多语言支持,同时不牺牲英语性能或可扩展性,以满足更广泛的用户群体的需求,这些用户群体涵盖了各种语言和应用。
图 1. 参数少于 10 亿的开源多语言嵌入模型的单向量密集检索性能。分数是 MTEB Retrieval 和 CLEF (ELRA, 2006) 子集(涵盖英语、法语、西班牙语、意大利语和德语)上的平均 nDCG@10。
多语言,不妥协
在这次 Arctic Embed 2.0 发布中,我们发布了两个可供使用的变体,一个中等变体侧重于推理效率,它构建于阿里巴巴的 GTE-multilingual 之上,具有 3.05 亿个参数(其中 1.13 亿个是非嵌入参数),另一个大型变体侧重于检索质量,它构建于 Facebook 的 XMLR-Large 的长上下文变体之上,具有 5.68 亿个参数(其中 3.03 亿个是非嵌入参数)。两种尺寸都支持高达 8,192 个 Token 的上下文长度。在构建 Arctic Embed 2.0 时,我们认识到许多现有多语言模型面临的挑战:针对多种语言进行优化通常最终会牺牲英语检索质量。这导致该领域的许多模型为每个版本都有两个变体:英语和多语言。Arctic Embed 2.0 模型有所不同。它们在德语、西班牙语和法语等非英语语言中提供顶级的性能,同时在英语检索方面也优于其仅英语的前身 Arctic Embed M 1.5。
通过仔细平衡多语言需求与 Snowflake 对卓越英语检索的承诺,我们构建了 Arctic Embed 2.0,使其成为通用的主力模型,适用于广泛的全球用例。在本文中,所有定性评估均指跨任务的平均 NDCG@10 分数,除非另有说明。

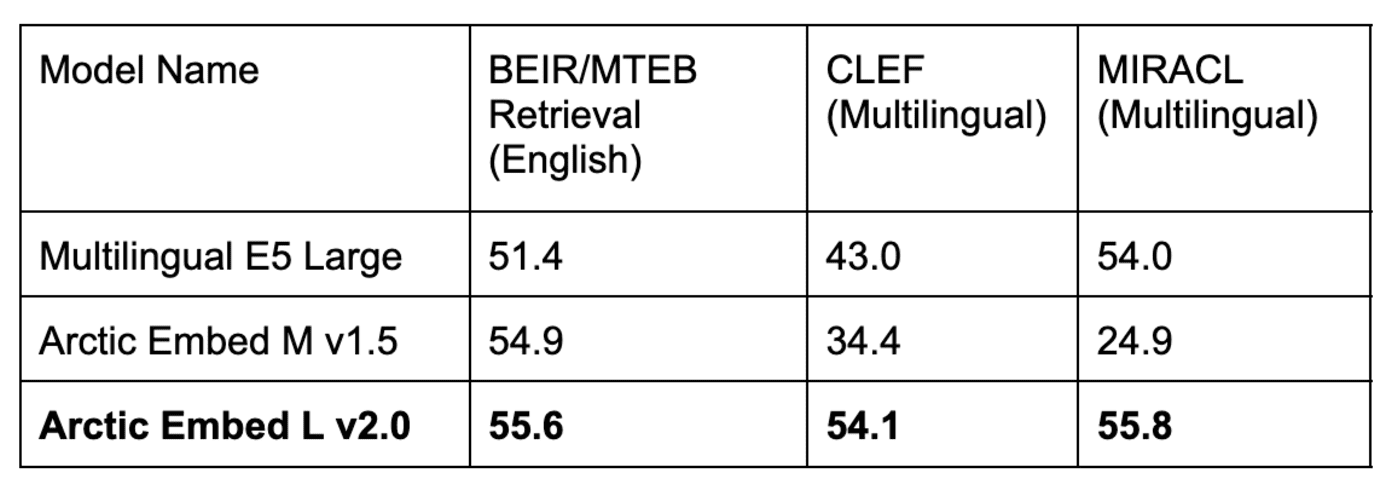
表 1. 我们的 Arctic Embed L v2.0 模型在流行的英语 MTEB Retrieval 基准测试中取得了高分,同时在多个多语言基准测试中也取得了很高的检索质量。Arctic Embed 的先前迭代在英语方面表现良好,但在多语言方面表现不佳,而流行的开源多语言模型在英语性能方面有所下降。所有模型和数据集的分数都反映了平均 NDCG@10。CLEF 和 MIRACL 分数反映了德语 (DE)、英语 (EN)、西班牙语 (ES)、法语 (FR) 和意大利语 (IT) 的平均值。
Arctic Embed 2.0 的多样化和强大的功能集
- 企业级吞吐量和效率: Arctic Embed 2.0 模型专为大规模企业需求而构建。即使是我们的“大型”模型,其参数也远低于 10 亿,并提供快速、高吞吐量的嵌入功能。根据内部测试,它在 NVIDIA A10 GPU 上可以轻松处理每秒 100 多个文档(平均),并实现低于 10 毫秒的查询嵌入延迟,从而可以在经济实惠的硬件上进行实际部署。
- 毫不妥协的英语和非英语检索质量: 尽管尺寸紧凑,但两个 Arctic Embed 2.0 模型在各种英语和非英语基准数据集上都取得了令人印象深刻的 NDCG@10 分数,这表明即使对于未包含在训练方案中的语言,它们也具有良好的泛化能力。这些令人印象深刻的基准分数使 Arctic Embed L 2.0 成为前沿检索模型中的领导者。
- 通过 Matryoshka Representation Learning (MRL) 实现可扩展的检索: Arctic Embed 2.0 版本包括 Arctic Embed 1.5 中引入的相同的量化友好型 MRL 功能,允许用户在对大型数据集执行搜索时降低成本并优化规模。借助两种模型尺寸,用户可以使用每个向量仅 128 字节(比 OpenAI 流行的 text-embedding-3-large 模型的未压缩嵌入小 96 倍 ^1^ )实现高质量检索。就像 Arctic Embed 1.5 一样,Arctic Embed 2.0 模型在压缩状态下也优于几个支持 MRL 的同行,具有显着更低的质量下降和更高的基准分数。
- 真正的开源: Arctic Embed 2.0 模型在宽松的 Apache 2.0 许可下发布。
开源的灵活性满足企业级的可靠性
与其前身一样,Arctic Embed 2.0 模型在宽松的 Apache 2.0 许可下发布,使组织能够在熟悉的许可下进行修改、部署和扩展。这些模型开箱即用,通过可靠的多语言嵌入在各个垂直领域支持应用,并且具有良好的泛化能力。
Hugging Face 首席执行官 Clément Delangue 表示:“多语言嵌入模型对于使全球各地的人们(不仅仅是英语使用者)成为 AI 构建者至关重要。通过在 Hugging Face 上以开源形式发布这些最先进的模型,Snowflake 为 AI 和世界做出了巨大贡献。”
事实上,尤其是在开源选项中,Arctic Embed 2.0 系列因其在多语言检索基准测试中的观察到的泛化能力而值得特别关注。通过许可 2000-2003 年跨语言评估论坛 (CLEF) 的测试套件,我们的团队能够衡量各种开源模型的域外检索质量,并发现了一个不幸的趋势,即与在域内 MIRACL 评估集上获得的分数相比,性能不佳。我们假设一些早期的开源模型开发人员可能在无意中过度调整了他们的训练方案,以提高 MIRACL 性能为代价,从而可能过度拟合了 MIRACL 训练数据。有关 Arctic Embed 2.0 模型是如何训练的以及我们在训练过程中学到了什么,请关注即将发布的技术报告。
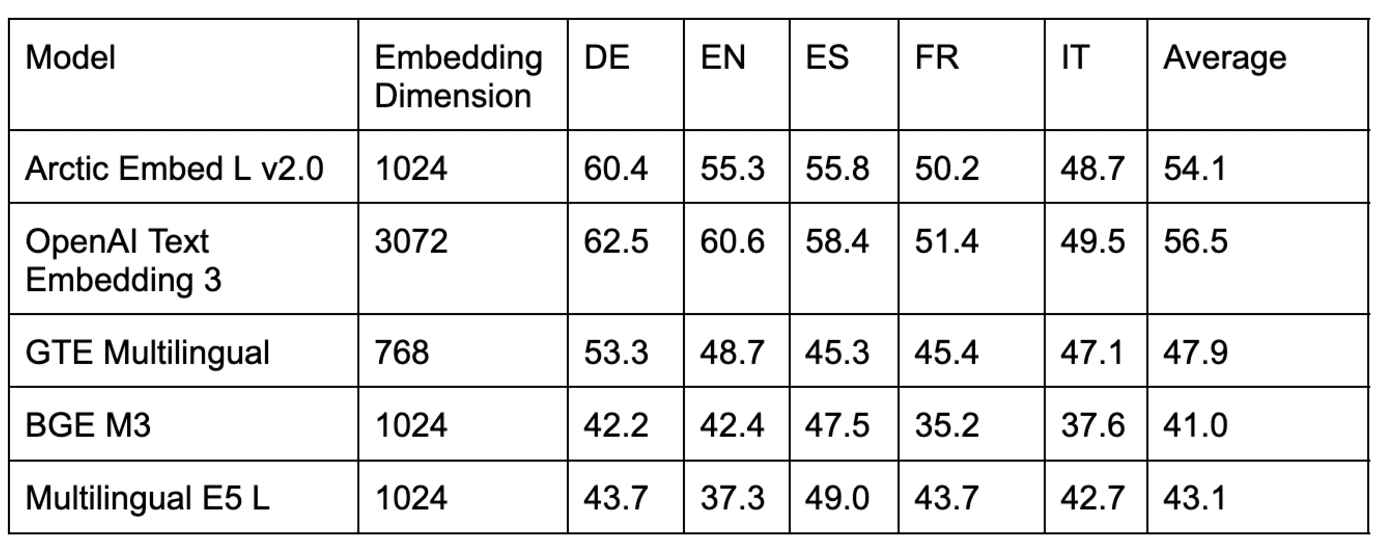
表 2. 在来自域外 CLEF 基准测试的几个数据集上比较多语言检索模型。
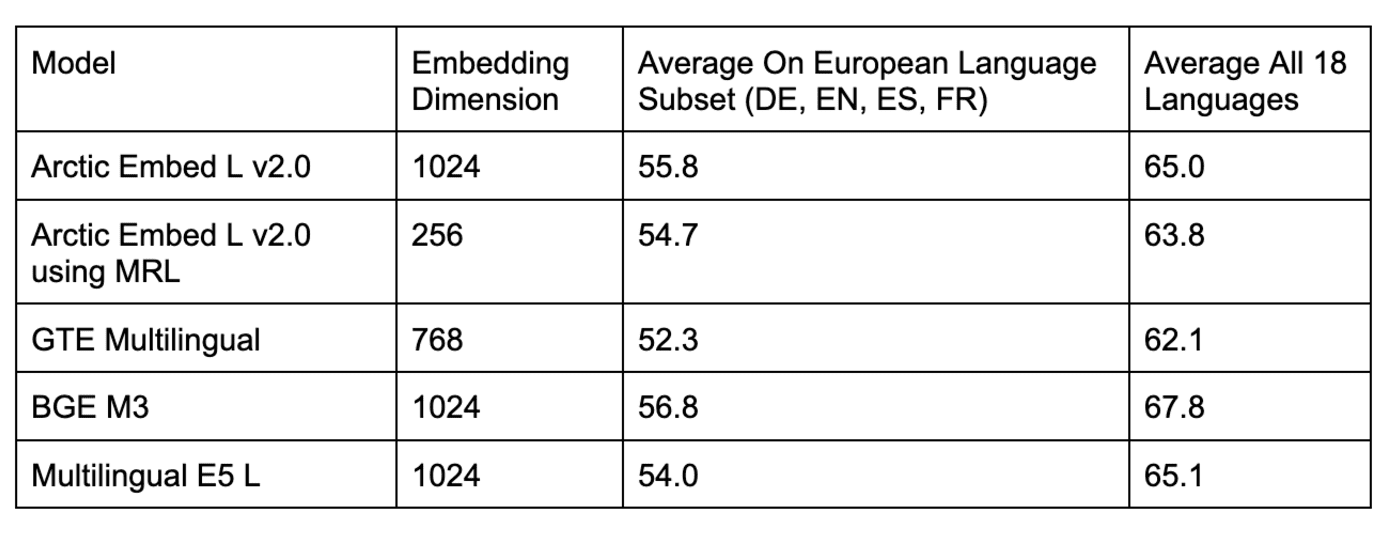
表 3. 在域内 MIRACL 基准测试中比较几个开源多语言检索模型。
如表 2 和表 3 所示,几个流行的开源模型在域内 MIRACL 评估中与 Arctic Embed L 2.0 的得分相当,但在域外 CLEF 评估中表现不佳。我们还对流行的闭源模型(如 OpenAI 的 text-embedding-3-large 模型)进行了基准测试,发现 Arctic L 2.0 的性能与领先的专有模型一致。
如表 4 所示,现有的开源多语言模型在流行的英语 MTEB Retrieval 基准测试中也比 Arctic Embed L 2.0 的得分更差,这迫使那些希望支持多种语言的用户在较低的英语检索质量或使用第二个模型仅用于英语检索的更多操作复杂性之间做出选择。随着 Arctic Embed 2.0 的发布,从业者现在能够切换到单个开源模型,而不会牺牲英语检索质量。
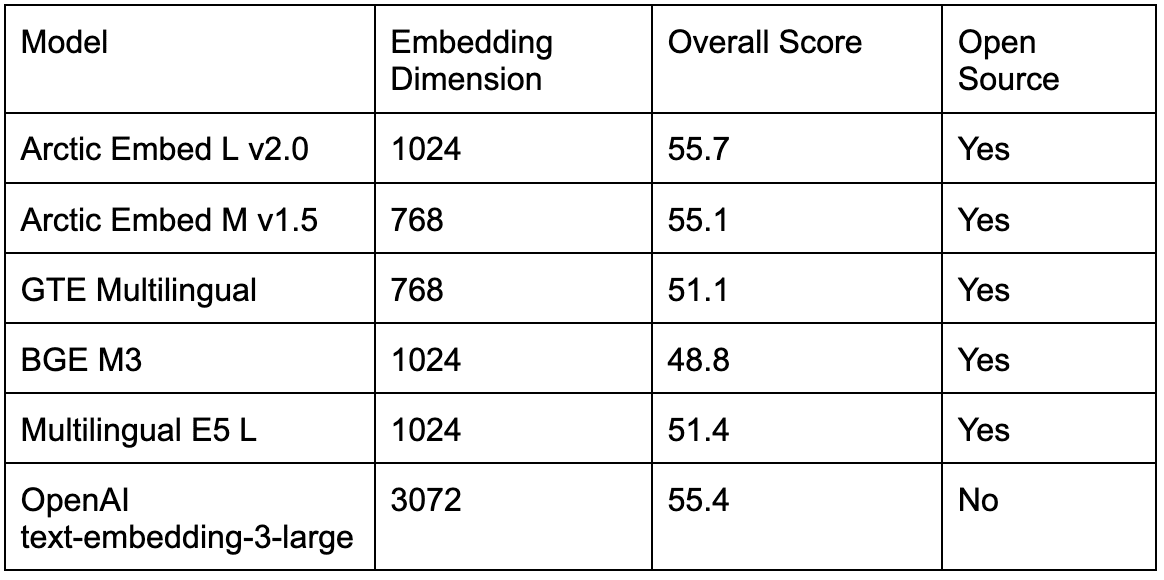
表 4. 在域内 MTEB Retrieval 基准测试中比较几个顶级开源和闭源多语言检索模型。
无需权衡的压缩和效率
Snowflake 继续在其嵌入模型设计中优先考虑效率和规模。借助 Arctic Embed L 2.0,用户可以将大型模型的质量特征压缩到每个向量仅需 128 字节存储的紧凑嵌入中。这使得在低端硬件上以较低的成本为数百万个文档提供检索服务成为可能。我们还通过将 Arctic Embed 2.0 令人印象深刻的检索质量分别压缩到其两种尺寸(中型和大型)的 1 亿和 3 亿个非嵌入参数中来实现嵌入吞吐量方面的效率 – 这仅比我们早期的仅英语版本略有增加。
事实上,以规模为重点的机制是 Arctic Embed L 2.0 真正发光的地方,与其他 MRL 训练的模型(如 OpenAI 的 text-embedding-3-large)相比,它在压缩下实现了更好的质量。
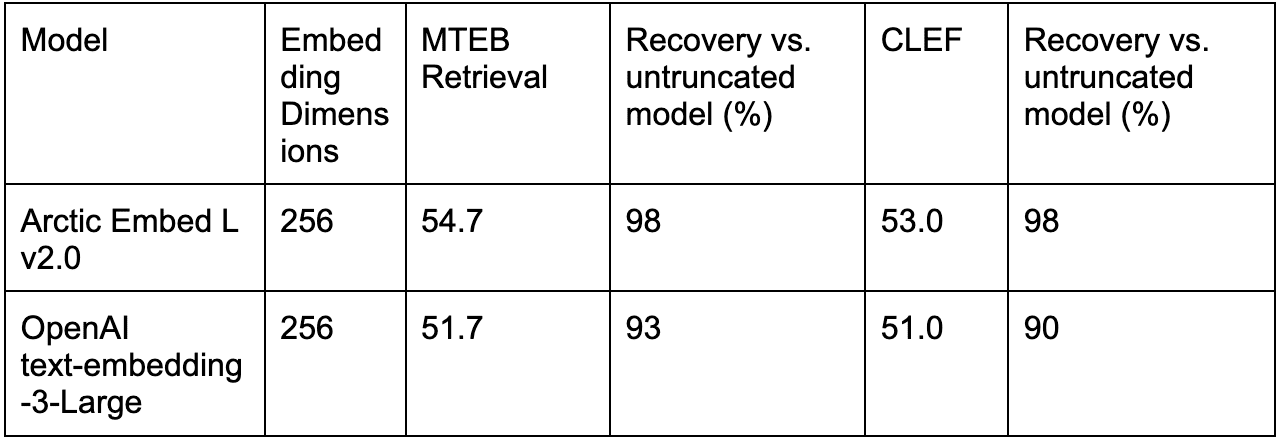
表 5. 将 OpenAI 的 text-embedding-3-large 性能与截断的嵌入与仅英语(MTEB Retrieval)和多语言(CLEF)的 Arctic Embed L 2.0 进行比较。
结论:多语言、高效检索的新标准
借助 Arctic Embed 2.0,Snowflake 为多语言、高效嵌入模型设定了新标准。此外,我们使文本嵌入质量的前沿不仅高效,而且也获得了宽松的开源。无论您的目标是扩大对多语言用户的覆盖范围、降低存储成本还是在可访问的硬件上嵌入文档,Arctic Embed 2.0 都提供了满足您需求的功能和灵活性。
我们即将发布的技术报告将更深入地探讨 Arctic Embed 2.0 背后的创新。与此同时,我们邀请您立即开始使用 Snowflake 进行嵌入。
^1^ 此计算对未压缩基线使用 float32 格式,即 3,072 个每个 32 位的数字,每个向量总共 98,304 位,正好比存储在 int4 格式的 Arctic Embed 2.0 模型中 MRL 截断的 256 维向量时使用的每个向量 1,024 位(相当于每个向量 128 字节)大 96 倍。
